
By: Dan Moore, Eric Sun, LV Lu, Xinyu Liu
Tl;dr : Coinbase is leveraging AWS’ Managed Streaming for Kafka (MSK) for ultra low latency, seamless service-to-service communication, data ETLs, and database Change Data Capture (CDC). Engineers from our Data Platform team will further present this work at AWS’ November 2021 Re:Invent conference.
Abstract
At Coinbase, we ingest billions of events daily from user, application, and crypto sources across our products. Clickstream data is collected via web and mobile clients and ingested into Kafka using a home-grown Ruby and Golang SDK. In addition, Change Data Capture (CDC) streams from a variety of databases are powered via Kafka Connect. One major consumer of these Kafka messages is our data ETL pipeline, which transmits data to our data warehouse (Snowflake) for further analysis by our Data Science and Data Analyst teams. Moreover, internal services across the company (like our Prime Brokerage and real time Inventory Drift products) rely on our Kafka cluster for running mission-critical, low-latency (sub 10 msec) applications.
With AWS-managed Kafka (MSK), our team has mitigated the day-to-day Kafka operational overhead of broker maintenance and recovery, allowing us to concentrate our engineering time on core business demands. We have found scaling up/out Kafka clusters and upgrading brokers to the latest Kafka version simple and safe with MSK. This post outlines our core architecture and the complete tooling ecosystem we’ve developed around MSK.
Configuration and Benefits of MSK
Config:
- TLS authenticated cluster
- 30 broker nodes across multiple AZs to protect against full AZ outage
- Multi-cluster support
- ~17TB storage/broker
- 99.9% monthly uptime SLA from AWS
Benefits:
Since MSK is AWS managed, one of the biggest benefits is that we’re able to avoid having internal engineers actively maintain ZooKeeper / broker nodes. This has saved us 100+ hours of engineering work as AWS handles all broker security patch updates, node recovery, and Kafka version upgrades in a seamless manner. All broker updates are done in a rolling fashion (one broker node is updated at a time), so no user read/write operations are impacted.
Moreover, MSK offers flexible networking configurations. Our cluster has tight security group ingress rules around which services can communicate directly with ZooKeeper or MSK broker node ports. Integration with Terraform allows for seamless broker addition, disk space increases, configuration updates to our cluster without any downtime.
Finally, AWS has offered excellent MSK Enterprise support, meeting with us on several occasions to answer thorny networking and cluster auth questions.
Performance:
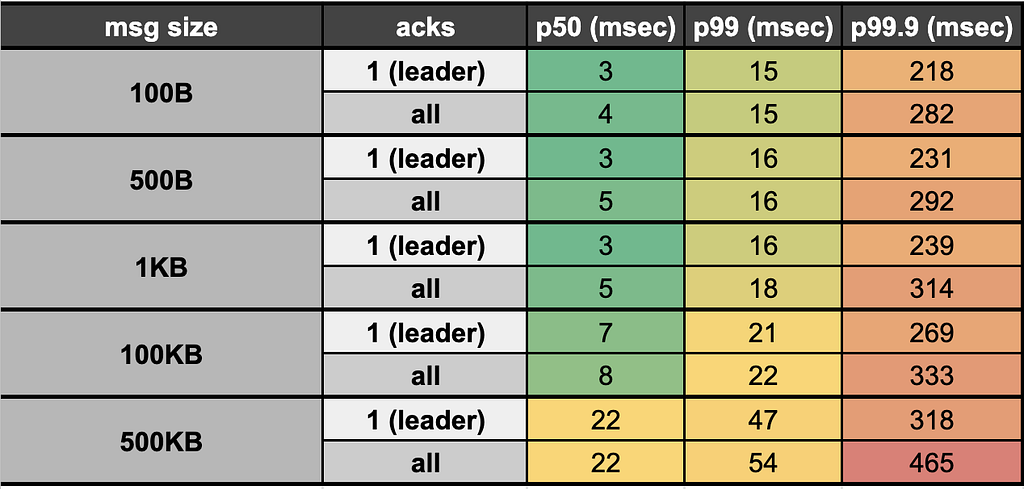
We reduced our end-to-end (e2e) latency (time taken to produce, store, and consume an event) by ~95% when switching from Kinesis (~200 msec e2e latency) to Kafka (<10msec e2e latency). Our Kafka stack’s p50 e2e latency for payloads up to 100KB averages <10 msec (in-line with LinkedIn as a benchmark , the company originally behind Kafka). This opens doors for ultra low latency applications like our Prime Brokerage service. Full latency breakdown from stress tests on our prod cluster, by payload size, presented below:
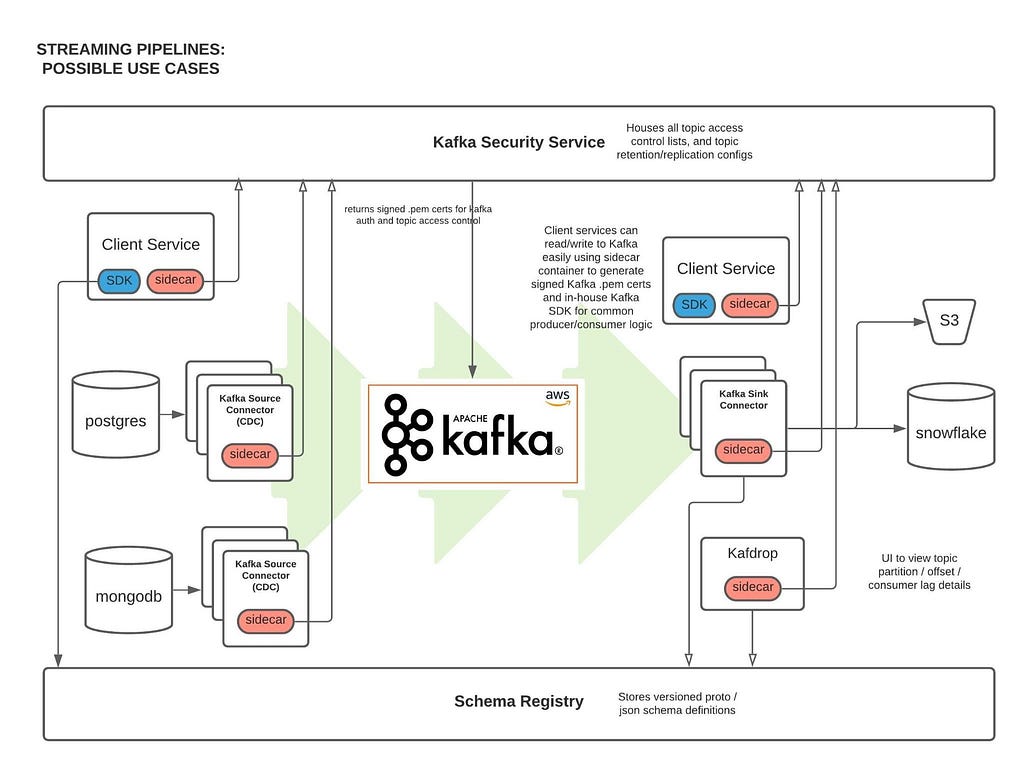
Proprietary Kafka Security Service (KSS)
What is it?
Our Kafka Security Service (KSS) houses all topic Access Control Lists (ACLs). On deploy, it automatically syncs all topic read/write ACL changes with MSK’s ZooKeeper nodes; effectively, this is how we’re able to control read/write access to individual Kafka topics at the service level.
KSS also signs Certificate Signing Requests (CSRs) using the AWS ACM API . To do this, we leverage our internal Service-to-Service authentication (S2S) framework, which gives us a trustworthy service_id from the client; We then use that service_id and add it as the Distinguished Name in the signed certificate we return to the user.
With a signed certificate, having the Distinguished Name matching one’s service_id, MSK can easily detect via TLS auth whether a given service should be allowed to read/write from a particular topic. If the service is not allowed (according to our acl.yml file and ACLs set in ZooKeeper) to perform a given action, an error will occur on the client side and no Kafka read/write operations will occur.
Also Required
Parallel to KSS, we built a custom Kafka sidecar Docker container that: 1) Plugs simply into one’s existing docker-compose file 2) Auto-generates CSRs on bootup and calls KSS to get signed certs, and 3) Stores credentials in a Docker shared volume on user’s service, which can be used when instantiating a Kafka producer / consumer client so TLS auth can occur.
Rich Data Stream Tooling
We’ve extended our core Kafka cluster with the following powerful tools:
Kafka Connect
This is a distributed cluster of EC2 nodes (AWS autoscaling group) that performs Change Data Capture (CDC) on a variety of database systems. Currently, we’re leveraging the MongoDB, Snowflake, S3, and Postgres source/sink connectors. Many other connectors are available open-source through Confluent here
Kafdrop
We’re leveraging the open-source Kafdrop product for first-class topic/partition offset monitoring and inspecting user consumer lags: source code here
Cruise Control
This is another open-source project, which provides automatic partition rebalancing to keep our cluster load / disk space even across all broker nodes: source code here
Confluent Schema Registry
We use Confluent’s open-source Schema Registry to store versioned proto definitions (widely used along Coinbase gRPC): source code here
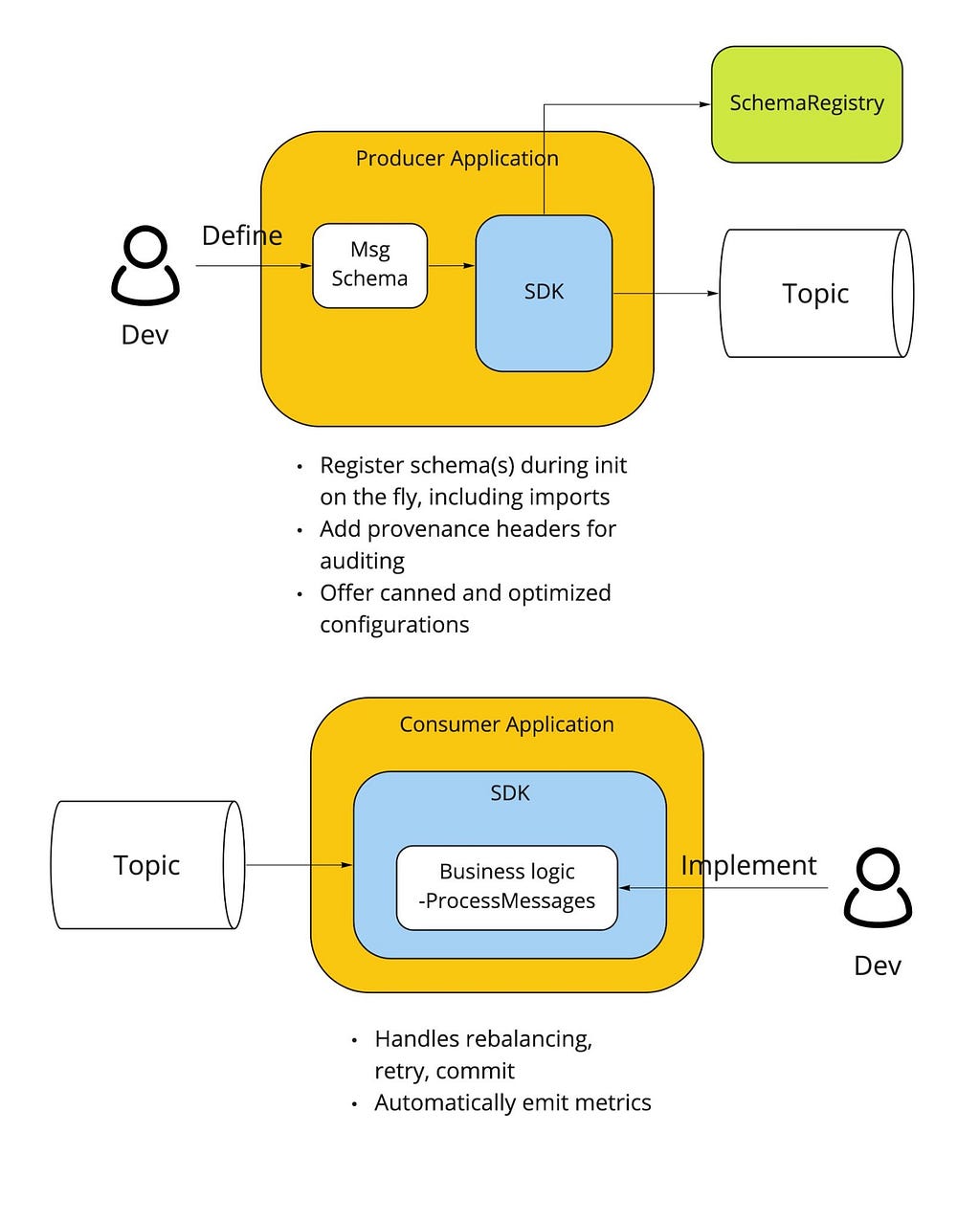
Internal Kafka SDK
Critical to our streaming stack is a custom Golang Kafka SDK developed internally, based on the segmentio/kafka release . The internal SDK is integrated with our Schema Registry so that proto definitions are automatically registered / updated on producer writes. Moreover, the SDK gives users the following benefits out of the box:
- Consumer can automatically deserialize based on magic byte and matching SR record
- Message provenance headers (such as service_id, event_time, event_type) which help conduct end-to-end audits of event stream completeness and latency metrics
- These headers also accelerate message filtering and routing by avoiding the penalty of deserializing the entire payload
Streaming SDK
Beyond Kafka, we may still need to make use of other streaming solutions, including Kinesis, SNS, and SQS. We introduced a unified Streaming-SDK to address the following requirements:
- Delivering a single event to multiple destinations, often described as ‘fanout’ or ‘mirroring’. For instance, sending the same message simultaneously to a Kafka topic and an SQS queue
- Receiving messages from one Kafka topic, emitting new messages to another topic or even a Kinesis stream as the result of data processing
- Supporting dynamic message routing, for example, messages can failover across multiple Kafka clusters or AWS regions
- Offering optimized configurations for each streaming platform to minimize human mistakes, maximize throughput and performance, and alert users of misconfigurations
Upcoming
On the horizon is integration with our Delta Lake which will fuel more performant, timely data ETLs for our data analyst and data science teams. Beyond that, we have the capacity to 3x the number of broker nodes in our prod cluster (30 -> 90 nodes) as internal demand increases — that is a soft limit which can be increased via an AWS support ticket.
Takeaways
Overall, we’ve been quite pleased with AWS MSK. The automatic broker recovery during security patches, maintenance, and Kafka version upgrades along with the advanced broker / topic level monitoring metrics around disk space usage / broker CPU, have saved us hundreds of hours provisioning and maintaining broker and ZooKeeper nodes on our own. Integration with Terraform has made initial cluster configuration, deployment, and configuration updates relatively painless (use 3AZs for your cluster to make it more resilient and prevent impact from a full-AZ outage).
Performance has exceeded expectations, with sub 10msec latencies opening doors for ultra high-speed applications. Uptime of the cluster has been sound, surpassing the 99.9% SLA given by AWS. Moreover, when any security patches take place, it’s always done in a rolling broker fashion, so no read/write operations are impacted (set default topic replication factor to 3, so that min in-sync replicas is 2 even with node failure).
We’ve found building on top of MSK highly extensible having integrated Kafka Connect, Confluent Schema Registry, Kafdrop, Cruise Control, and more without issue. Ultimately, MSK has been beneficial for both our engineers maintaining the system (less overhead maintaining nodes) and unlocking our internal users and services with the power of ultra-low latency data streaming.
If you’re excited about designing and building highly-scalable data platform systems or working with cutting-edge blockchain data sets (data science, data analytics, ML), come join us on our mission building the world’s open financial system: careers page .
How we scaled data streaming at Coinbase using AWS MSK was originally published in The Coinbase Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
